set.seed(123) # for reproducibility
x <- runif(50, 0, 30) # x vector
y <- runif(50, 0, 30) # y vector
dat <- data.frame(x,y) # dataframe for plotting16 Spatial patterns
16.1 Definitions
A spatial disease pattern can be defined as the arrangement of diseased entities relative to each other and to the architecture of the host crop (Madden et al. 2007). Such arrangement is the realization of the underlying dispersal of the pathogen, from one or several sources within and/or outside the area of interest, under the influence of physical, biological and environmental factors.
The study of spatial patterns is conducted at a specific time or multiple times during the epidemic. When assessed multiple times, both spatial and temporal processes can be characterized. Because epidemics change over time, it is expected that spatial patterns are not constant but change over time as well. Usually, plant pathologists are interested in determining spatial patterns at one or various spatial scales, depending on the objective of the study. The scale of interest may be a leaf or root, plant, field, municipality, state, country or even intercontinental area. The diseased units observed may vary from lesions on a single leaf to diseased fields in a large production region.
The patterns can be classified into two main types that occur naturally: random or aggregated. The random pattern originates because the chances for the units (leaf, plant, crop) to be infected are equal and low, and are largely independent from each other. In aggregated spatial patterns, such chances are unequal and there is dependency among the units. For example, a healthy unit close to a diseased unit is at higher risk than more distant units.
Let’s simulate in R two vectors (x,y) for the positions of diseased units that follow a random or an aggregated pattern. For the random pattern, we use runif, a function which generates random deviates from the uniform distribution.
Now, the plot to visualize the random pattern.
library(tidyverse)
library(r4pde)
theme_set(theme_r4pde())
pr <- dat |> # R base pipe operator
ggplot(aes(x, y))+
theme_r4pde(font_size = 12)+
geom_point(size =3,
color = "darkred")+
ylim(0,30)+
xlim(0,30)+
coord_fixed()+
labs(x = "Distance x", y = "Distance y",
title = "Random")
pr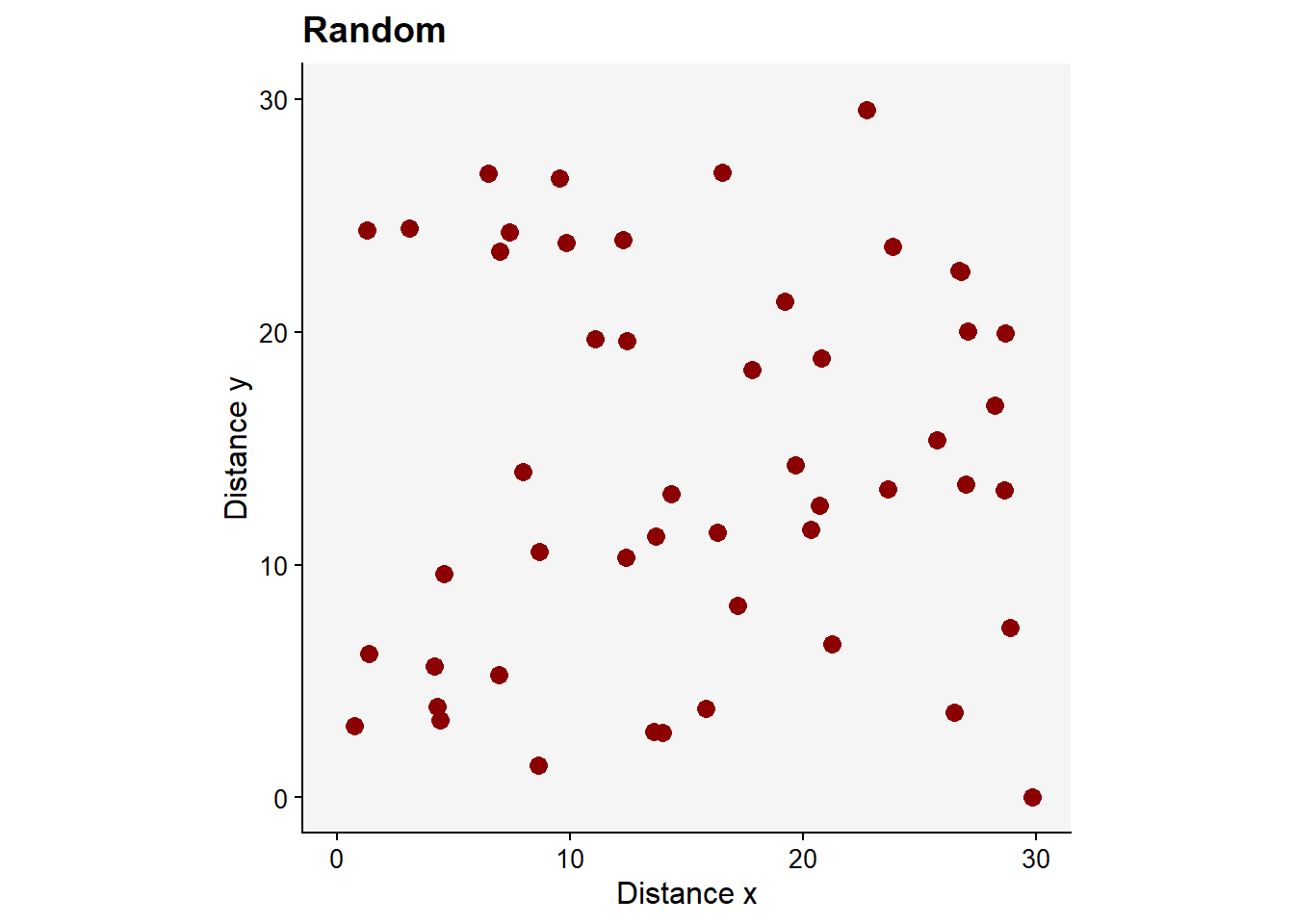
Now, we can generate new x and y vectors using rnbinom function which allows generating values for the negative binomial distribution (which should give rise to aggregated patterns) with parameters size and prob. Let’s simulate 50 values with mean 12 and size 20 as dispersal parameter.
x <- rnbinom(n = 50, mu = 12, size = 20)
y <- rnbinom(n = 50, mu = 5, size = 20)
dat2 <- data.frame(x, y)This should give us an aggregated pattern.
pag <- dat2 |>
ggplot(aes(x, y))+
theme_r4pde(font_size = 12)+
geom_point(size = 3, color = "darkred")+
ylim(0,30)+
xlim(0,30)+
coord_fixed()+
labs(x = "Distance x", y = "Distance y",
title = "Aggregated")
pag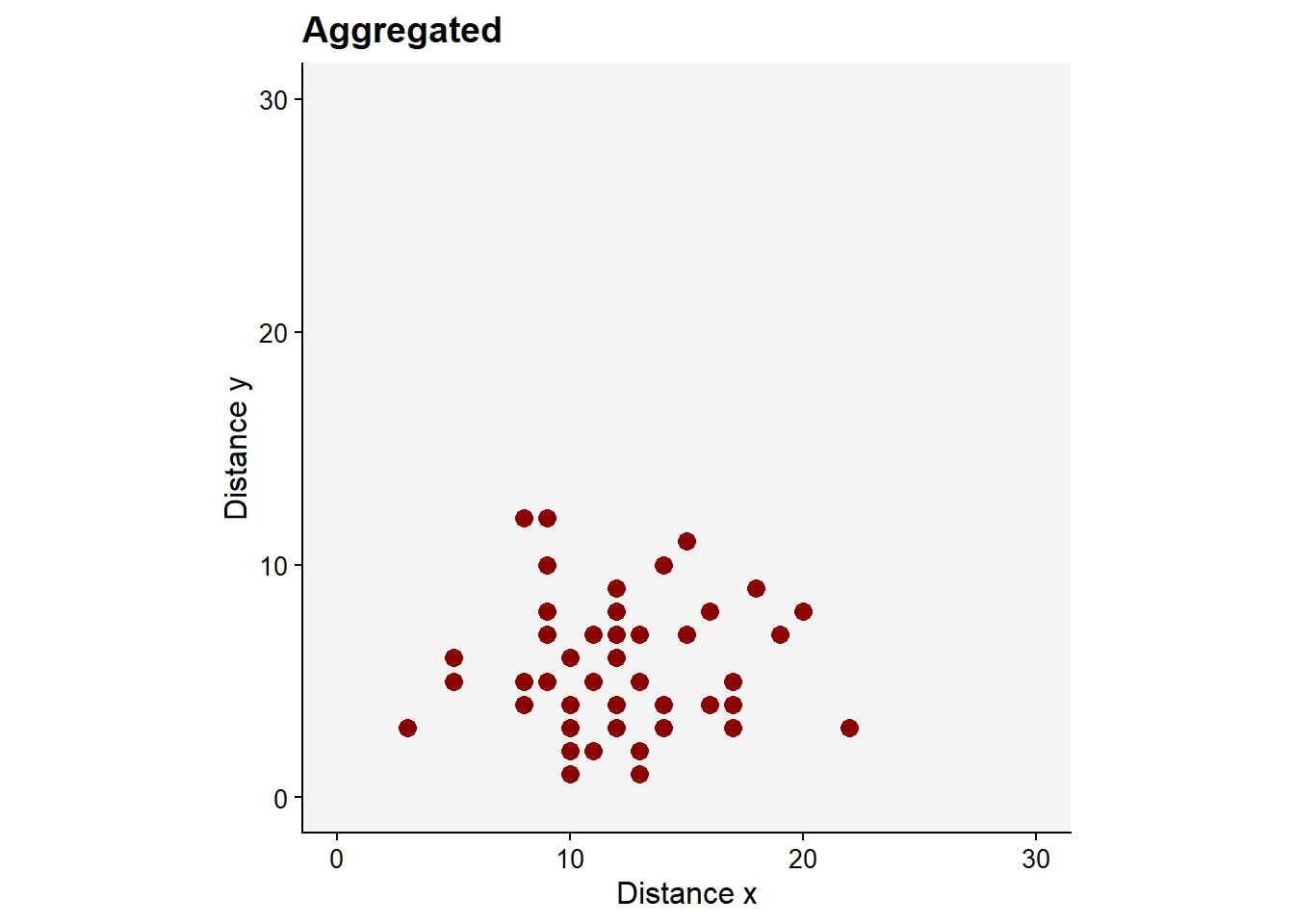
A rare pattern found in nature is the regular pattern, but it may be generated artificially by the man when conducting experimentation. Follows a code to produce the regular pattern.
x <- rep(c(0,5,10,15,20, 25, 30, 35, 40, 45), 5)
y <- rep(c(0, 5, 10, 15, 20, 25, 30, 35, 40, 45), each = 10)
dat3 <- data.frame(x, y)
preg <- dat3 |>
ggplot(aes(x, y))+
theme_r4pde(font_size = 12)+
geom_point(size = 3, color = "darkred")+
ylim(0,30)+
xlim(0,30)+
coord_fixed()+
labs(x = "Distance x", y = "Distance y",
title = "Regular")
pregWarning: Removed 51 rows containing missing values or values outside the scale range
(`geom_point()`).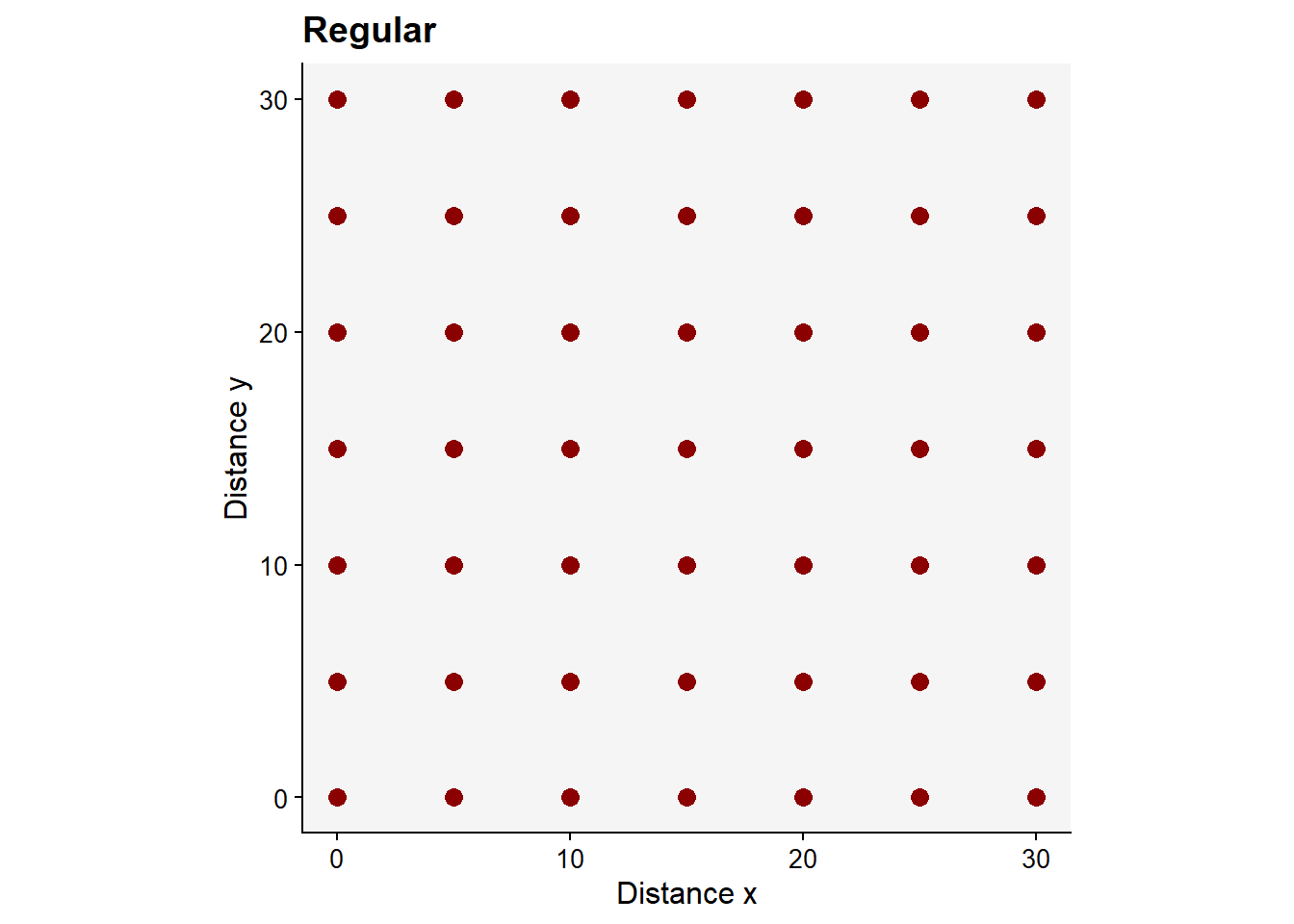
library(patchwork)
preg + pr + pag
ggsave("imgs/spatial.png", width = 10, height = 4)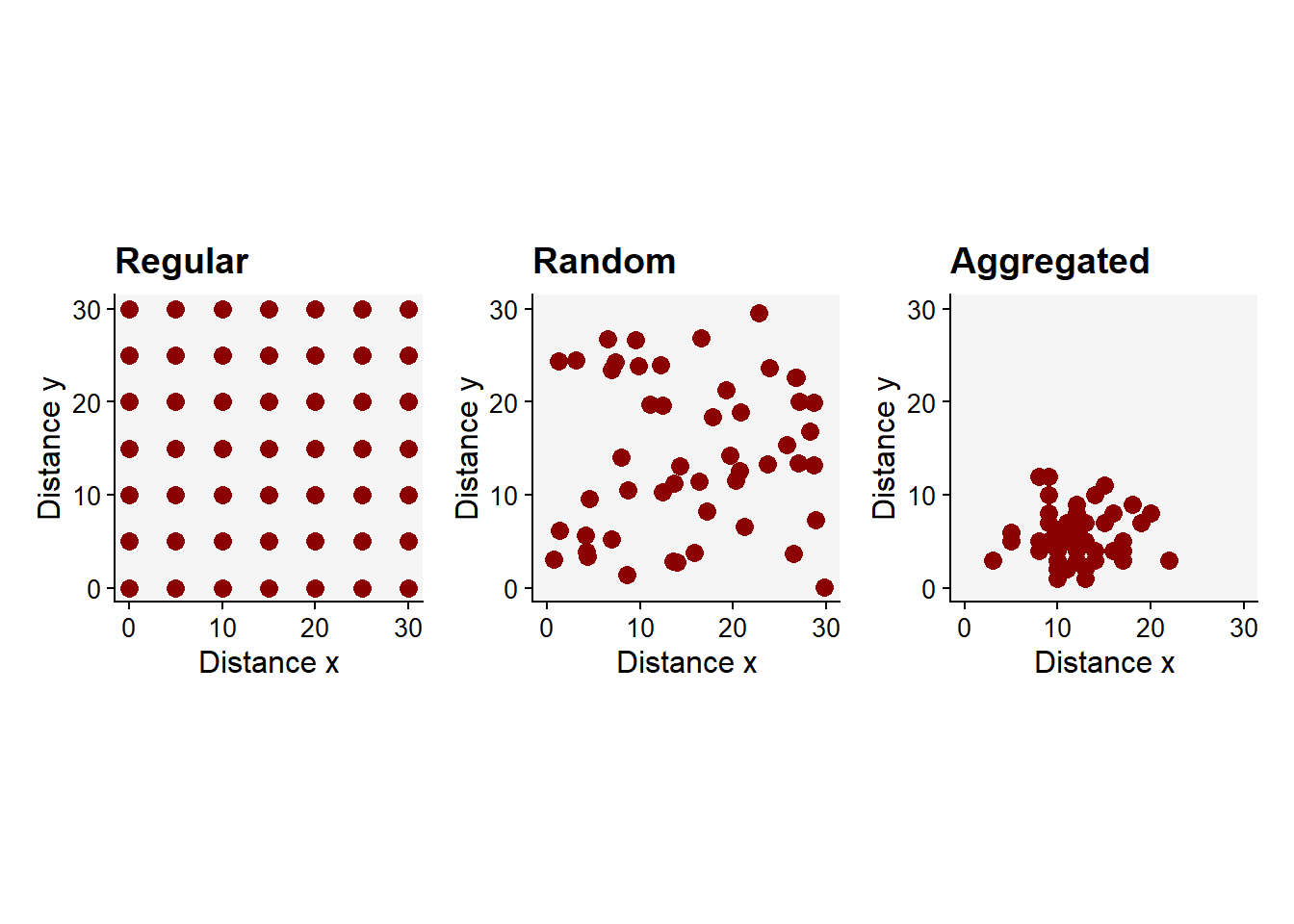
16.2 Spatiotemporal
The location of diseased plants can be assessed over time and so we can appraise both the progress and pattern of the epidemics. Let’s visualize spatial data collected from actual epidemics monitored (plant is diseased or not diseased) during six times during the epidemics. The data is available in the epiphy R package. Let’s use only one variety and one irrigation type.
library(epiphy)
tswv_1928 <- tomato_tswv$field_1928
tswv_1928 |>
filter(variety == "Burwood-Prize"&
irrigation == "trenches") |>
ggplot(aes(x, y, fill= factor(i)))+
geom_tile(color = "black")+
coord_fixed()+
scale_fill_manual(values = c("grey70", "darkred"))+
labs(fill = "Status", title = "")+
theme_void()+
theme(legend.position = "bottom")+
facet_wrap(~ t, nrow =1)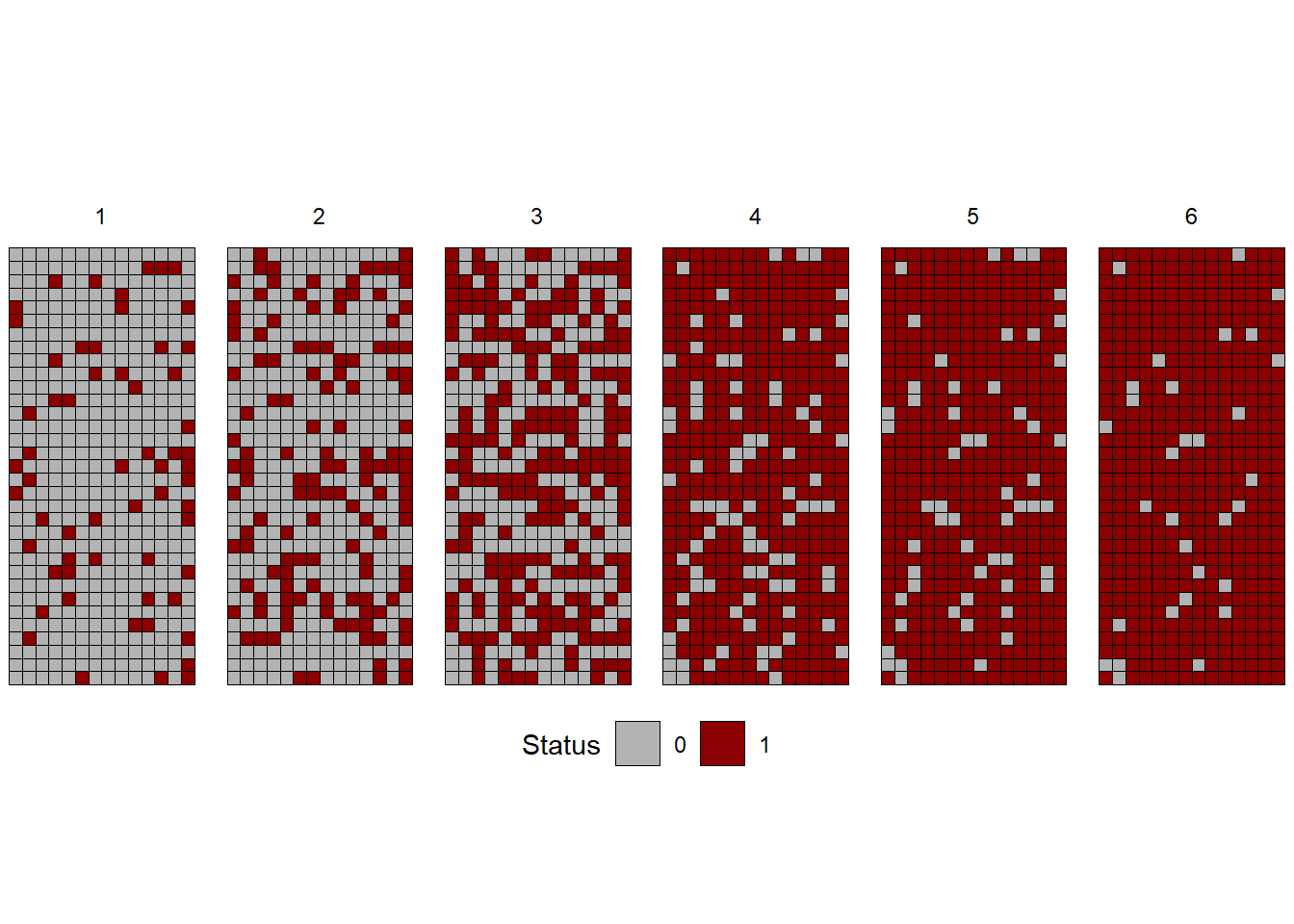
In this other example, the severity of gummy stem blight (Didymella bryoniae) of watermelon (Café-Filho et al. 2010) was recorded in a 0-4 ordinal scale over time (days after planting) and space, in a naturally-infected rain-fed commercial field, to evaluate the effect of the distance of initial inoculum on the intensity of the disease. The dataset is included in the {r4pde} package that accompanies the book.
library(r4pde)
df <- DidymellaWatermelon
df |>
ggplot(aes(NS_col, EW_row, fill = severity))+
coord_fixed()+
geom_tile (color = "white")+
theme_void()+
theme(legend.position = c(0.9,0.25))+
scale_fill_gradient(low = "grey70", high = "darkred")+
facet_wrap(~ dap, ncol = 4)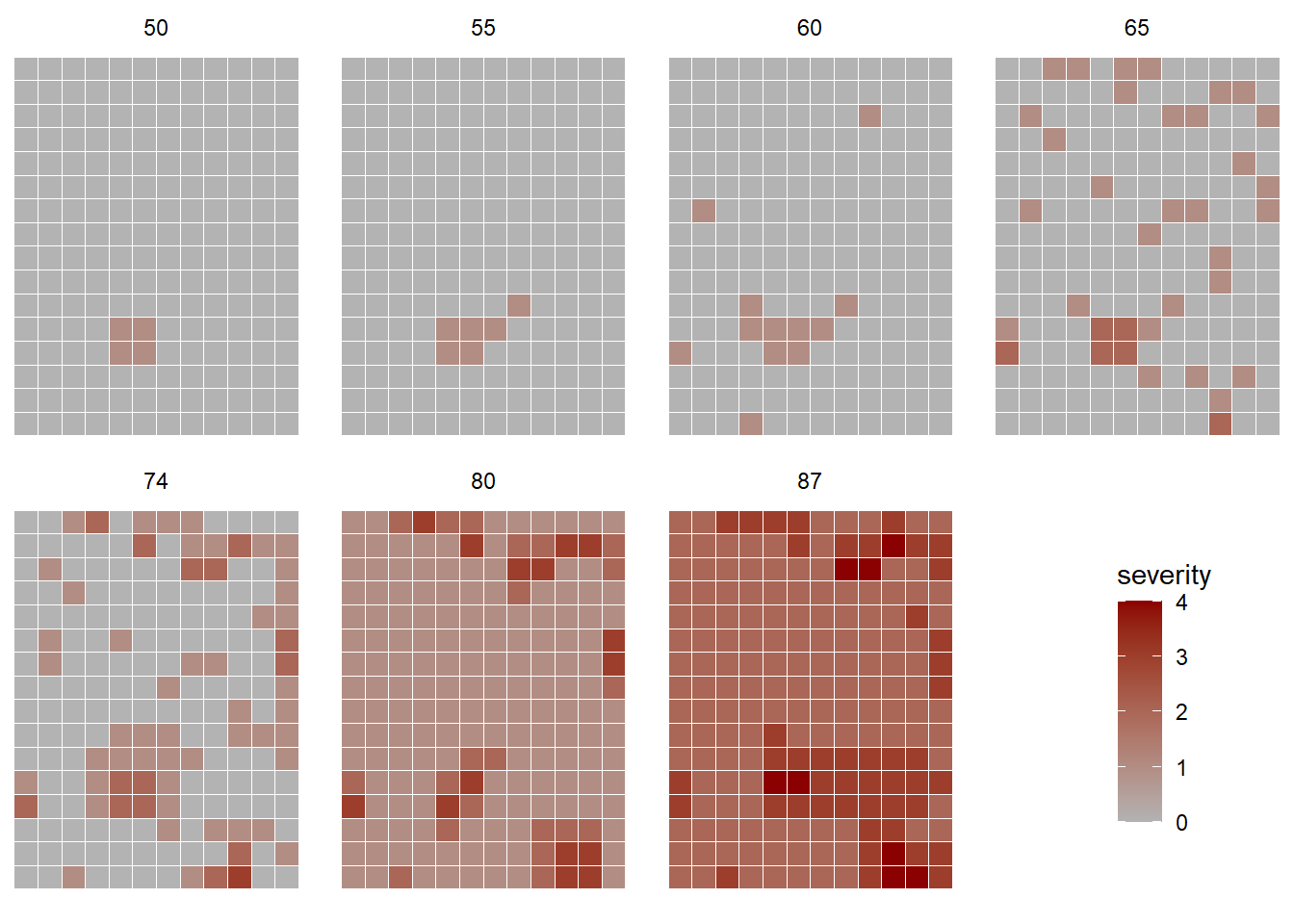
We can see that the disease spread from the initial focus detected at 50 days after planting, taking the entire field 37 days later with various levels of severity.
16.3 Simulating spatial patterns
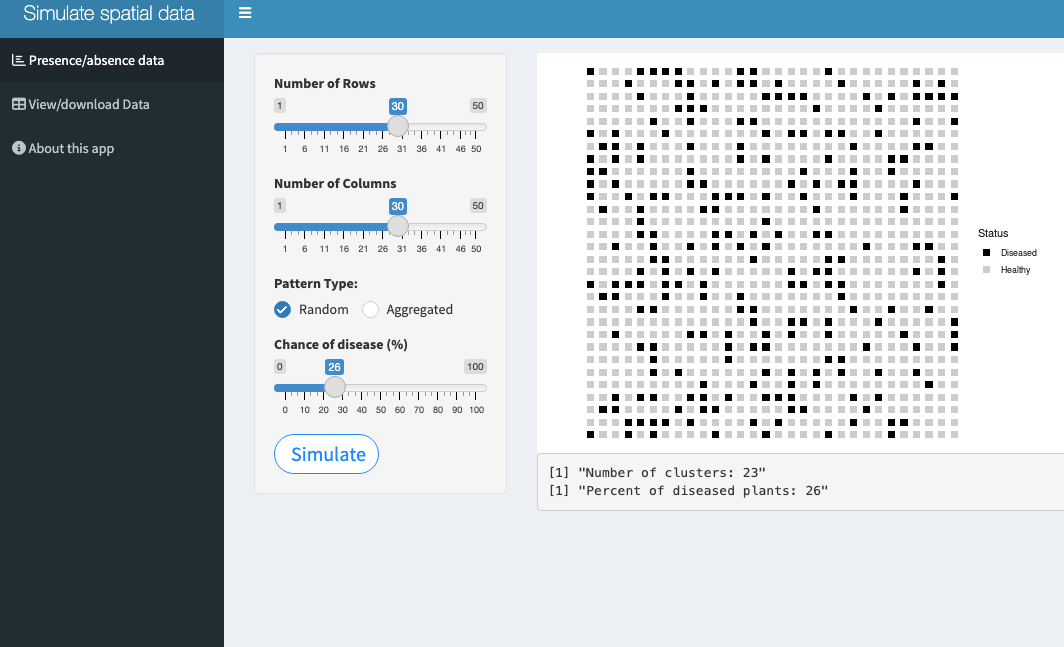
Two Shiny apps have been developed to allow simulating various spatial disease patterns. The first generates a disease- or pathogen-only data where the units are located in a scatter plot where the user can define the number of cells of the grid as well as the number of points to be plotted and the realized pattern: random or aggregated.
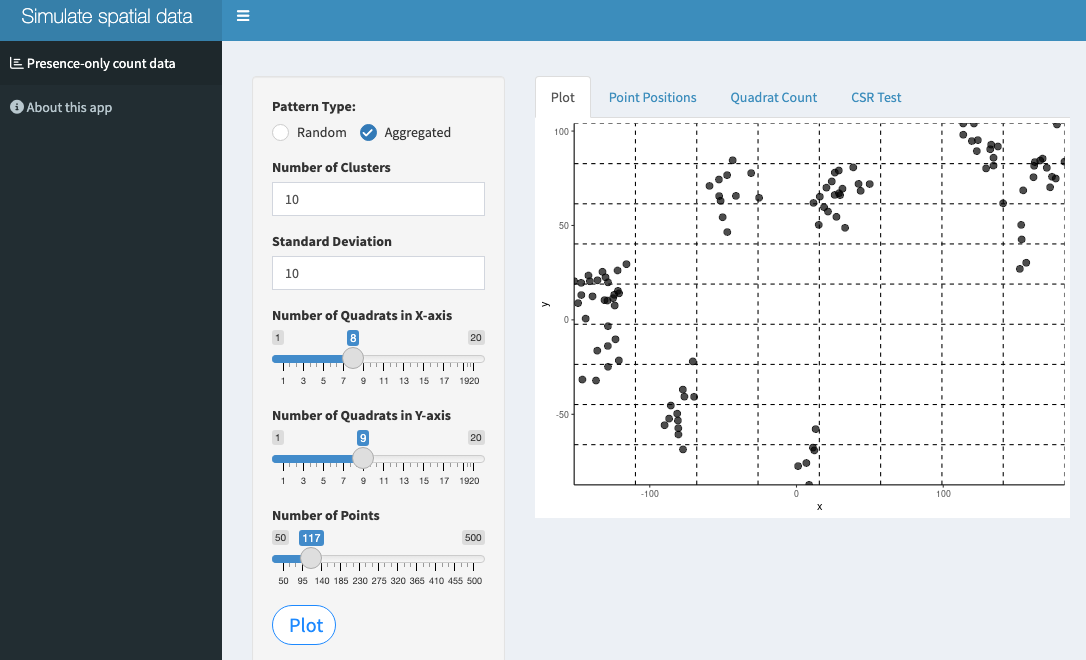
The second app generates an artificial plantation with presence-absence data in a 2D map. The user can define the number of rows and number of plants per row and the realized pattern: random or aggregated. The latter pattern can start from the center or border of the plantation. The app calculates the number of foci and the final incidence (proportion of diseased plants).